XML Publisher
Overview: Oracle XML Publisher is a template-based publishing solution delivered with the Oracle E-Business Suite. It provides a new approach to report design and publishing by integrating familiar desktop word processing tools with existing E-Business Suite data reporting. At runtime, XML Publisher merges the custom templates with the concurrent request data extracts to generate output in PDF, HTML, RTF, EXCEL (HTML), or even TEXT for use with EFT and EDI transmissions
Basic Need for XML: Consider the following scenarios
We have a RDF report with tabular layout which prints in English
New Requirements:
- User1 wants the same Report needs to be printed in Spanish
- User2 wants the Same Report needs to be printed in chart format
- User3 wants the Same Report output in Excel
- User4 wants the Same Report output to be published on intranet or internet
- User5 wants the Same Report output eliminating few columns and adding few other
A new RDF needs to be created for each requirement stated above or an existing RDF needs to be modified with huge amount of effort but where as with XML Publisher it can be done very easily.
XML Publisher separates a report’s data, layout and translation components into three manageable pieces at design time; at runtime all the three pieces are brought back together by XML Publisher to generate the final formatted, translated outputs like PDF, HTML, XLS and RTF. In future, if any there is any change in layout we just need to add/modify the Layout file
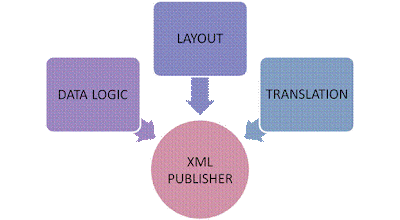
Data Logic – Data extracted from database and converted into an XML string.
Layout - The layout templates to be used for the final output are stored and managed in the Template Manager.
Translation -The translation handler will manage the translation that is required at runtime
In brief the steps are as follows:-
a. Create a procedure and register it as Concurrent Program so that we write XML tags into output file.
b. Build a Data Definition & XML Template using XML Publisher.
c. Create a relation between XML Template & Concurrent Program and run the concurrent program
Requirements for XML Data Object Reports
- Oracle XML Publisher Release 5.5 patch 4206181
- Template Builder 5.5
Template builder is used to create template/layout for your report. Usually Template builder 5.5 is available in Oracle XML Publisher patch itself but you can also download it from http://edelivery.oracle.com. First select Oracle Application Server Products then select your platform and then locate the Oracle® XML Publisher Release 5.6.2 Media Pack v1 for Microsoft Windows, as below:
Download the Desktop edition from the below:
When you download the XML Publisher Desktop edition you get a Zip file containing setup for XML Publisher Desktop Install Shield, this installs some components into Microsoft Word.
After installing, the Word Add-Ins is attached to the menu bar for the word document. This menu lets you attach an XML data source document, add the XML data to your template, set preferences and preview the output.
In detail along with screenshots:-
A concurrent program is written that spit out an XML file as output Such concurrent program can be of type SQL or PL/SQL or Oracle Report or any other supportable type, provided it can produce a XML output.
1.Here I have a very simple PL/SQL procedure, which fetch the records from AR tables and write the output in xml tags.
CREATE OR REPLACE PROCEDURE APPS.Demo_XML_Publisher(errbuf VARCHAR2,retcode NUMBER,v_customer_id VARCHAR2)
AS
/*Cursor to fetch Customer Records*/
CURSOR xml_parent
IS
SELECT customer_name , customer_id
FROM ra_customers
WHERE customer_id = to_number(v_customer_id);
/*Cursor to fetch customer invoice records*/
CURSOR xml_detail(p_customer_id1 NUMBER)
IS
SELECT ra.customer_trx_id customer_trx_id, ra.ship_to_customer_id ship_to_customer_id, ra.trx_number trx_number,aps.amount_due_original ams
FROM ra_customer_trx_all ra, ar_payment_schedules_all aps
WHERE ra.ship_to_customer_id = p_customer_id1
AND aps.customer_trx_id = ra.customer_trx_id
AND ROWNUM<4;
BEGIN
/*First line of XML data should be ‘’*/
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'');
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'');
FOR v_customer IN xml_parent
LOOP
/*For each record create a group tag at the start*/
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'');
/*Embed data between XML tags for ex:- ABCD*/
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'' || v_customer.customer_name
|| '');
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'' || v_customer.customer_id ||
'');
FOR v_details IN xml_detail(v_customer.customer_id)
LOOP
/*For customer invoices create a group tag at the
start*/
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'');
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'' ||
v_details.customer_trx_id || '');
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'' ||
v_details.ship_to_customer_id || '');
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,''||
v_details.trx_number||'');
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,''||
v_details.trx_number||'');
/*Close the group tag at the end of customer invoices*/
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'');
END LOOP;
/*Close the group tag at the end of customer record*/
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'');
END LOOP;
/*Finally Close the starting Report tag*/
FND_FILE.PUT_LINE(FND_FILE.OUTPUT,'');
exception when others then
FND_FILE.PUT_LINE(FND_FILE.log,'Entered into exception');
END Demo_XML_Publisher;
/
2. Create an executable SampleXmlReport for the above procedure Demo_XMML_Publisher.
Go to Application Developer Responsibility->Concurrent->Executable

3. Create a new concurrent program SampleXmlReport that will call the SampleXmlReport executable declared above. Make sure that output format is placed as XML.
Go to Application Developer Responsibility -> Concurrent ->Program

4. Make sure we declare the parameters for the procedure.

5. Add this new concurrent program with Receivables request group. Either using the following code or through below application screen.
DECLARE
BEGIN
FND_PROGRAM.add_to_group
(
PROGRAM_SHORT_NAME =>'CUST_XML_SAMPLE'
,PROGRAM_APPLICATION =>'AR'
,REQUEST_GROUP => 'Receivables All'
,GROUP_APPLICATION =>'AR'
) ;
commit;
exception
when others then
dbms_output.put_line('Object already exists');
END ;
/
Page 1|2 Next>>










{kind=link}
{kind=link}
{kind=link}
{kind=link}